dropwhile関数はイテレータの条件がTrueの間の要素を破棄(drop)しFalseになった以降のイテレータを保持(take)する関数です。イテレータ要素のTrue、Falseの判定は関数を用いて判定します。途中で1回でもFalseになればそれ以降の要素は判定がTrueになってもすべて保持されます。
dropwhile関数がわからなくてこのページに来た人は「dropwhile関数とは」を見てください。活用例を知りたい人は「dropwhileの利用例」を見てください。
 【Python】【図解】dropwhile関数
【Python】【図解】dropwhile関数dropwhile関数はイテレータの条件がTrueの間の要素を破棄(drop)しFalseになった以降のイテレータを保持(take)する関数です。イテレータ要素のTrue、Falseの判定は関数を用いて判定します。途中で1回でもFalseになればそれ以降の要素は判定がTrueになってもすべて保持されます。
dropwhile関数がわからなくてこのページに来た人は「dropwhile関数とは」を見てください。活用例を知りたい人は「dropwhileの利用例」を見てください。
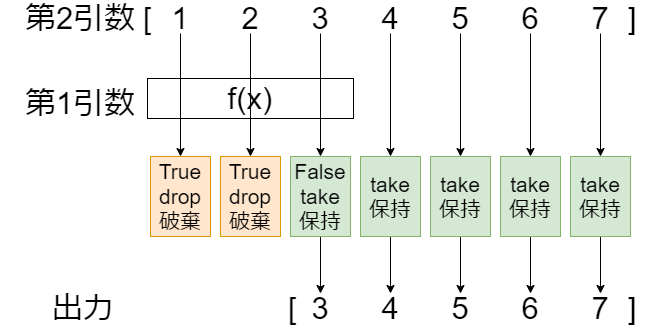
dropwhile関数は第1引数の条件判定関数の結果がTrueの間の要素を破棄しFalseになった以降のイテレータを保持するイテレータ生成関数です。
from itertools import dropwhile
def f(x):
return x%3
for i in dropwhile(f,[1,2,3,4,5,6,7]):
print(i)
実行結果
3 4 5 6 7
リストの1,2までは関数fを実行した結果は1と2ですので真理値判定がTrueになります。3はfの結果が0になるため真理値判定はFalseになります。そのため3以降の3,4,5,6,7が出力されます。
実際には以下のようにラムダ式にすることも多いです。
from itertools import dropwhile
for i in dropwhile(lambda x: x % 3,[1,2,3,4,5,6,7]):
print(i)
実行結果
3 4 5 6 7
いくつか利用例を考えてみます。処理をおこなってエラーがあった際にNGをセットしてその後は処理をおこなわない場合、処理のおこなわれていないデータ以降を出力する場合。
タブルの右側に'NG'がでてくる以降のデータを出力する場合以下のようになります。
from itertools import dropwhile
data=[
(['鈴木',478,1995,4],'OK'),
(['佐藤',520,2003,7],'OK'),
(['田中',320,1999,],'NG'),
(['加藤',780,2001,8],'OK')]
for i in dropwhile(lambda x: x[1]=='OK',data):
print(i)
実行結果
(['田中', 320, 1999], 'NG') (['加藤', 780, 2001, 8], 'OK')
特定のディレクトリ名以下のディレクトリを出力する場合。例えば'suzuki'というフォルダ以降のパスを切り出す場合は以下のようになります。
from itertools import dropwhile
import os
data='C:\\User\\suzuki\\OneDrive'
l =os.sep.join([ i for i in dropwhile(lambda x: x!='suzuki',data.split(os.sep))])
print(l)
実行結果
suzuki\OneDrive
今回はdropwhile関数について記事にしてみました。特定条件より前を削除し、それ以降を残すような場合にはよく使いますので覚えておくと良いとおもいます。

この記事へのコメント
コメントはまだありません。
コメントを送る